
안녕하세요. 데이터 분석에 필요한 통계를 주제로도 포스팅을 해보려 합니다.
첫 번째 주제는 데이터 분석 결과에 대한 유의성을 판단하기 위한 t-검정(t-test)에 대해서 이야기 해보도록 하겠습니다.
1. t-test을 해야 하는 이유?
t-test은 2개 집단의 평균 값의 차이가 통계적으로 같은 집단인지, 다른 집단인지 비교하기 위해 사용하는 검정 방법입니다. 두 집단의 평균을 비교하는 분석 방법은 t-test 외에도 z-test가 있는데, z-test는 모집단의 분산을 알고 있는 경우에 사용됩니다. 하지만 우리는 일상에서 모집단의 분산을 알고 있는 경우는 거의 없기 때문에 t-test를 주로 사용합니다.
2. t-test의 종류
t-test는 아래와 같이 3가지 방법으로 구분 됩니다.
| 구분 | 정의 |
| 일표본 T 검정(One sample t-test) | 표본의 평균과 특정 기준값의 차이 분석 |
| 독립표본 T 검정(Independent sample t-test) | 독립된 두 표본(=집단)의 평균 차이 분석 |
| 대응표본 T 검정(Paired sample t-test) | 짝을 이룬 데이터의 평균 변화 분석 |
실무에서 t-test를 사용하는 몇 가지 예시는 다음과 같습니다.
1. A대학의 남학생 평균 키가 180cm와 같은지, 다른지 비교 (일표본 T-검정)
2. 고객 등급별 평균 매출액 차이 (독립표본 T-검정)
3. 강수여부에 따른 따릉이 평균 대여건수 차이 (독립표본 T-검정)
4. 고객 Loyalty Program 시행 전, 후에 따른 평균 매출액 차이 (대응표본 T-검정)
5. 신제품 출시에 따른 광고 전, 후 매출액의 차이 (대응표본 T-검정)
6. 두 가지 세일즈 교육 방법에 따른 영업사원의 판매실적 평균 차이 (대응표본 T-검정)
3. Python을 활용한 t-test 실습
데이터셋 : [Kaggle] Independent t-test example
사용하게 될 데이터는 학생들의 성별, 부모님의 학력 수준, 직업, 통학시간, 공부시간 등 다양한 독립변수들을 통해 종속변수인 시험성적을 예측할 수 있는 데이터셋 입니다. 우리는 여기서 성별에 따른 시험 평균점수 차이를 독립표본 T 검정을 통해 통계적으로 유의미한지 확인하려고 합니다.
1) 데이터 불러오기
[코드]
import pandas as pd # 사용할 데이터를 dataframe 형태로 불러옴
import scipy.stats as stats # t-test를 위한 라이브러리
data = pd.read_csv('data/student-mat.csv') # csv 파일 불러오기
print('data의 크기:', data.shape) # dataframe의 크기 확인
data.head() # dataframe의 처음 5개 행만 보여주기
[실행 결과]
data의 크기: (395, 33)
2) 데이터 전처리
[코드]
# 성별, 시험성적 데이터만 'exam'이라는 변수에 할당
exam = data[['sex', 'G1', 'G2', 'G3']]
# t-test를 위해 남성과 여성을 구분하여 새로운 변수에 재할당
male = exam[exam['sex'] == 'M']
female = exam[exam['sex'] == 'F']
3) 그룹별 기술통계값 확인(평균, 표준편차)
describe() 함수를 통해 남/여학생 시험 성적 결과에 대한 평균, 표준편차 값을 확인 할 수 있습니다.
[코드]
# 남학생 시험 성적에 대한 기술통계값
male.describe()
[실행 결과]
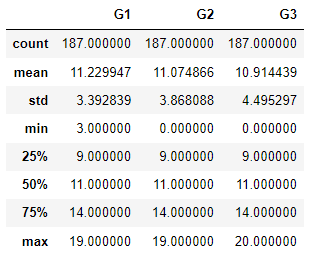
# 여학생 시험 성적에 대한 기술통계값
female.describe()
[실행 결과]
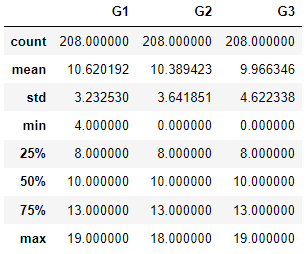
시험 성적만 놓고 봤을 때 총 세 번에 걸쳐 치뤄진 시험에서 남학생의 평균 점수가 여학생의 평균 점수가 모두 높은 것을 확인할 수 있습니다. 그렇다면 남학생이 여학생보다 시험 성적이 높다는 사실이 통계적으로 유의미한지 확인하기 위해 t-test를 실시해보도록 하겠습니다.
4) 독립표본 T 검정(Independent samples t-test)
Scipy 패키지를 활용해 독립표본 t 검정을 실시하도록 하겠습니다. 총 3개 시험(G1, G2, G3) 성적에 대한 남학생, 여학생의 평균 점수 차이가 통계적으로 유의한지 확인해겠습니다. 코드는 생각보다 간단합니다!
[코드]
print('G1에 대한 t-test 결과:', stats.ttest_ind(male['G1'], female['G1'], equal_var=True))
print('G2에 대한 t-test 결과:', stats.ttest_ind(male['G2'], female['G2'], equal_var=True))
print('G3에 대한 t-test 결과:', stats.ttest_ind(male['G3'], female['G3'], equal_var=True))
[실행 결과]
G1에 대한 t-test 결과: Ttest_indResult(statistic=1.8283673434285317, pvalue=0.06825227168840965)
G2에 대한 t-test 결과: Ttest_indResult(statistic=1.8135169726008136, pvalue=0.07051474229682837)
G3에 대한 t-test 결과: Ttest_indResult(statistic=2.061992815503971, pvalue=0.039865332341527636)
5) 결과 해석
남학생이 여학생보다 시험 성적이 높은 것이 유의미한 차이가 있는지 확인하기 위하여 위와 같이 독립표본 T 검정을 실시하였습니다. 총 세 번의 시험 중에서 G1, G2의 경우 p-value가 0.05보다 높아 통계적으로 유의미한 차이를 보이지 않는 것으로 나타났지만, G3의 경우 p-value가 0.05보다 작은 것으로 보아 통계적으로 유의미한 차이가 있는 것으로 볼 수 있을 것 같습니다. 하지만 전체적으로 봤을 때 앞선 두 차례의 시험에서 통계적으로 유의하지 않았기 때문에 남학생의 시험 성적이 여학생보다 좋다고 단정 짓기는 어려워 보입니다.
작성된 내용 중 잘못된 부분이나 궁금한 사항이 있다면 언제든지 피드백 부탁 드립니다.
감사합니다.
'Data > Statistics' 카테고리의 다른 글
| 통계 실습 : 다양한 통계분석 방법, 언제 사용할까? (0) | 2022.02.21 |
|---|---|
| 통계 실습 : One-way ANOVA (with 파이썬) (1) | 2022.02.16 |

